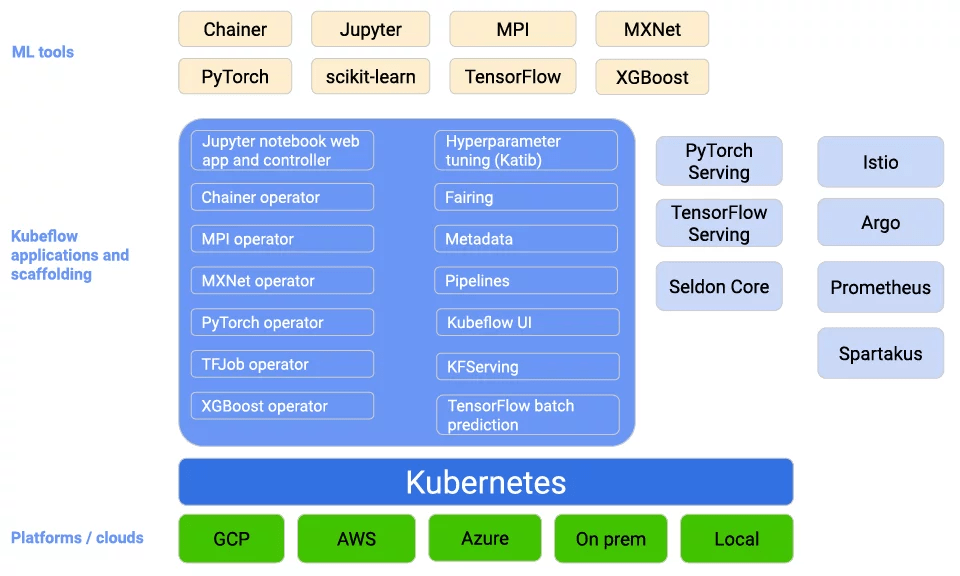
In the ever-evolving landscape of machine learning and artificial intelligence, orchestrating the complex dance of algorithms and data requires a platform that can seamlessly integrate and scale. Enter Kubeflow, an open-source framework designed to bring together the best of Kubernetes and machine learning. In this blog post, we’ll embark on a journey into the heart of Kubeflow, unraveling its architecture and exploring the interconnected components that make it a powerhouse for scalable and efficient machine learning workflows.
Kubeflow Architecture Overview:
At its core, Kubeflow leverages the scalability, flexibility, and container orchestration capabilities of Kubernetes. The architecture is designed to facilitate end-to-end machine learning workflows, from data preparation and model training to deployment and monitoring.
**1. Kubernetes as the Foundation:
Kubeflow builds on the robust foundation of Kubernetes, harnessing its container orchestration capabilities to provide a scalable and portable platform for deploying, managing, and scaling machine learning workloads.
**2. Kubeflow Core Components:
- Notebooks: The starting point for many data scientists, Kubeflow integrates Jupyter Notebooks for interactive and collaborative model development.
- Pipelines: Kubeflow Pipelines allow users to define, deploy, and manage end-to-end ML workflows using a visual interface, fostering collaboration between data scientists and ML engineers.
- Katib: This component automates hyperparameter tuning, exploring the hyperparameter space efficiently to enhance model performance.
- KFServing: Simplifying model deployment, KFServing provides a consistent and scalable serving experience for machine learning models.
**3. Kubeflow Custom Resource Definitions (CRDs):
Kubeflow extends Kubernetes by introducing Custom Resource Definitions (CRDs) specific to machine learning. These CRDs define custom objects like TrainingJob and Experiment, enabling users to manage machine learning resources in a Kubernetes-native way.
**4. Kubeflow Central Dashboard:
The central dashboard serves as the control center for Kubeflow, providing a unified interface for managing and monitoring machine learning experiments, deployments, and resources.
**5. Metadata and Model Tracking:
Kubeflow incorporates tools like Metadata and ModelDB to track experiments, manage model versions, and ensure transparency and traceability throughout the ML development lifecycle.
**6. Training Operators:
Kubeflow Training Operators standardize the interface for training jobs, allowing for efficient scaling and resource utilization.
Key Benefits of Kubeflow’s Architecture:
- Scalability: Leveraging Kubernetes, Kubeflow allows organizations to scale machine learning workloads seamlessly as demand grows.
- Modularity: The modular design of Kubeflow enables users to choose and integrate components based on their specific needs and requirements.
- Portability: Kubeflow’s reliance on containers ensures that ML models developed and trained in one environment can be easily deployed in another, enhancing portability.
- Collaboration: By providing a unified platform for data scientists and ML engineers, Kubeflow fosters collaboration and streamlines the ML development process.
Conclusion:
As we dissect the architecture of Kubeflow, it becomes evident that its strength lies in its ability to seamlessly integrate with Kubernetes while providing purpose-built components for machine learning workflows. Whether you’re a data scientist experimenting with models or an ML engineer deploying them into production, Kubeflow offers a cohesive platform that simplifies the complexities of AI development. Embrace the magic of Kubeflow, where architecture meets innovation, and every component contributes to a future where machine learning workflows are scalable, collaborative, and efficient.

Leave a comment